move back and forth between the box and the keyboard
move right 1.5 meters, then move left 3 meters, then move left 1.5 meters
move right 1.5 meters, then move left 3 meters, then move left 1.5 meters
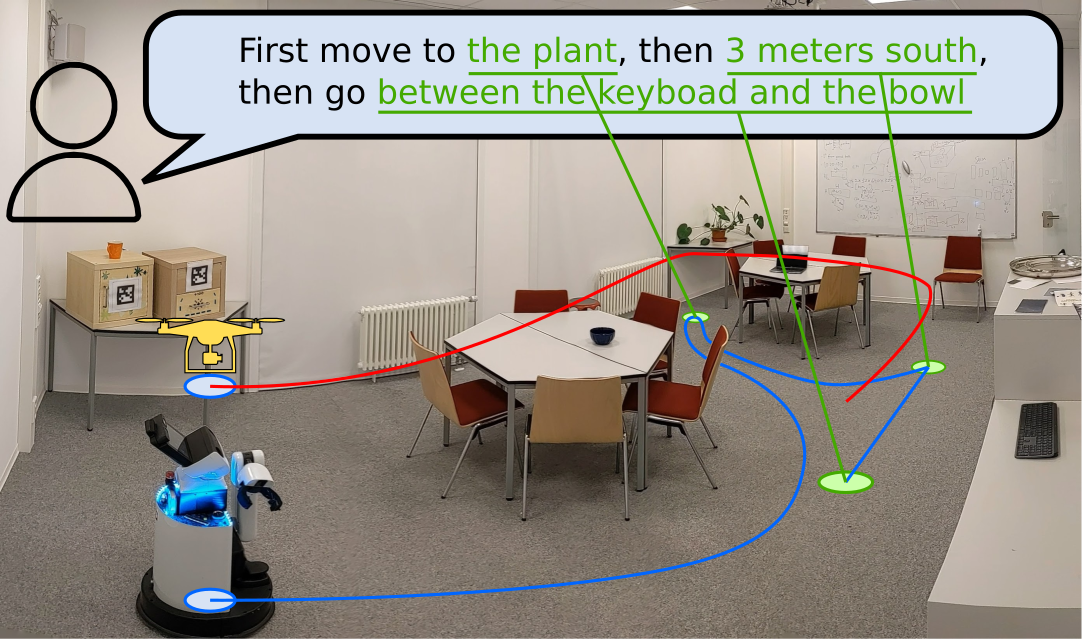
move to the plant
move in between the wooden box and the chair
Grounding language to the visual observations of a navigating agent can be performed using off-the-shelf visual-language models pretrained on Internet-scale data (e.g. image captions). While this is useful for matching images to natural language descriptions of object goals, it remains disjoint from the process of mapping the environment, so that it lacks the spatial precision of classic geometric maps. To address this problem, we propose VLMaps, a spatial map representation that directly fuses pretrained visual-language features with a 3D reconstruction of the physical world. VLMaps can be autonomously built from video feed on robots using standard exploration approaches and enable natural language indexing of the map without additional labeled data. Specifically, when combined with large language models (LLMs), VLMaps can be used to (i) translate natural language commands into a sequence of open-vocabulary navigation goals (which, beyond prior work, can be spatial by construction, e.g. "in between the sofa and TV" or "three meters to the right of the chair") directly localized in the map, and (ii) can be shared among multiple robots with different embodiments to generate new obstacle maps on-the-fly (by using a list of obstacle categories). Extensive experiments carried out in simulated and real world environments show that VLMaps enable navigation according to more complex language instructions than existing methods.
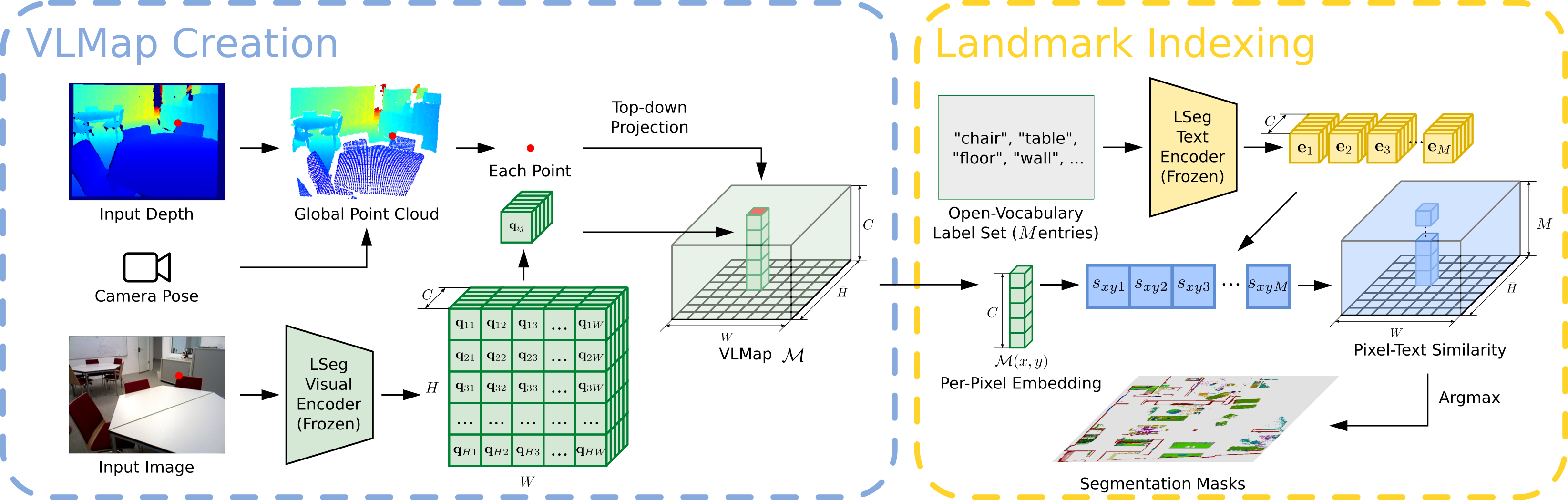
The key idea behind building a VLMap is to fuse pretrained visual-language features into a geometrical reconstruction of the scene. This can be done by computing dense pixel-level embeddings from an existing visual-language model (over the RGB-D video feed of the robot) and back-projecting them onto the 3D surface of the environment (captured from depth data used for reconstruction with visual odometry). Finally, we generate the top-down scene representation by storing the visual-language features of each image pixel in the corresponding grid map pixel location.
We encode the open-vocabulary landmark names ("chair", "green plant", "table" etc.) with the text encoder in the Visual Language Model. Then we align the landmark names with the pixels in the VLMap by computing the cosine similarity between their embeddings. We get the mask of each landmark type with the argmax operation on the similarity score.
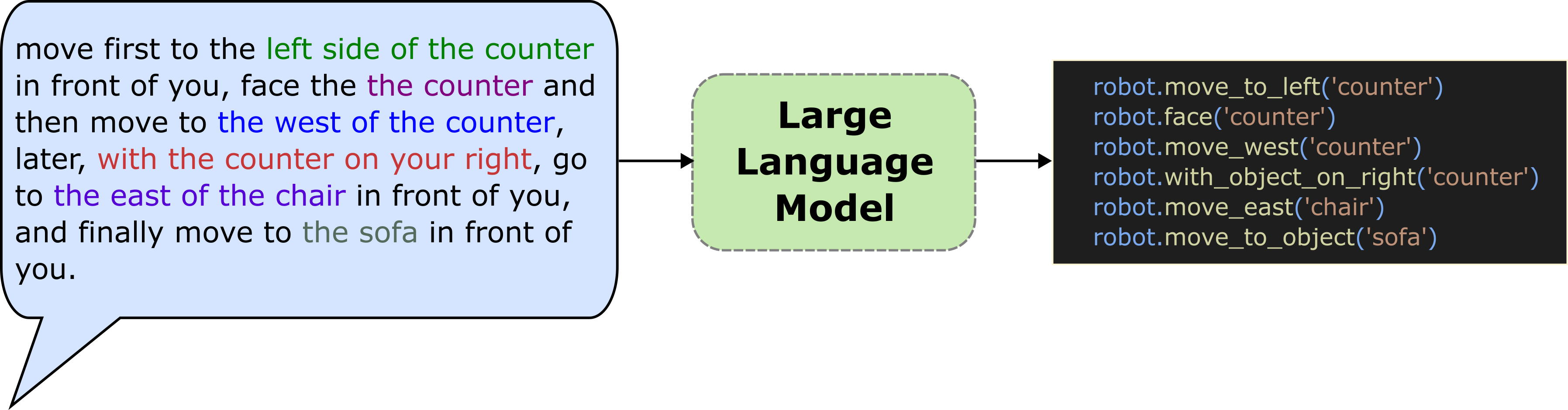
We generate the navigation policies in the form of executable code with the help of Large Language Models. By providing a few examples in the prompt, we exploit GPT-3 to parse language instructions into a string of executable code, expressing functions or logic structures (if/else statements, for/while loops) and parameterizing API calls (e.g., robot.move_to(target_name) or robot.turn(degrees)).
With open-vocabulary landmark indexing, VLMaps enables long-horizon spatial goal navigation with natural language instructions
Sequence 1
VLMaps
CLIP on Wheels
Sequence 2
VLMaps
CLIP on Wheels
A VLMap can be shared among different robots and enables generation of obstacle maps for different embodiments on-the-fly to improve navigation efficiency. For example, a LoCoBot (ground robot) has to avoid sofa, tables, chairs and so on during planning while a drone can ignore them. Experiments below show how a single VLMap representation in each scene can adapt to different embodiments (by generating customized obstacle maps) and improve navigation efficiency.
Move to the laptop and the box sequentially
Drone
LoCoBot
Move to the window
Drone
LoCoBot
Move to the television
Drone
LoCoBot
@inproceedings{huang23vlmaps,
title={Visual Language Maps for Robot Navigation},
author={Chenguang Huang and Oier Mees and Andy Zeng and Wolfram Burgard},
booktitle = {Proceedings of the IEEE International Conference on Robotics and Automation (ICRA)},
year={2023},
address = {London, UK}
}